

Layered architecture is one of the most used architecture styles. It consists of splitting an application into horizontal layers where each layer plays a specific role. As illustrated in the diagram below, common layers we found in applications are presentation, domain (or business), and data (or persistence).

The dependencies in this architecture are from top to down. The request originating from the presentation calls the code in the business layer, which then calls the persistence layer. No dependency is allowed in the other direction from bottom to top, as indicated in red arrows in the diagram below.
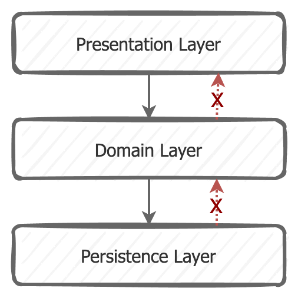
This architecture is generally easy to implement and provides a solid base if the separation of concerns and abstraction between layers are well respected.
Layered Architecture Limitations
One of the issues of this architecture is the dependency on the lower layers. Indeed, each change in the persistence layer impacts the business and even the presentation layers.
The domain layer contains the business logic of an application. It, therefore, can be considered the most important code in any application, and no one wants to change it because something else changes in the persistence code or any other layer. We want the business logic code independent of databases, external applications, and interfaces.
In addition, we want to have the business logic code easily testable, which may not be the case for the layered architecture. For example, we need to mock the persistence layer to test the business code.
Dependency Inversion Principle
A variation to layered architecture is to arrange your design so that the domain layer does not depend directly on the persistent layer by introducing an interface in the domain layer and using the Dependency Inversion Principle (DIP). We can then invert the dependency so it is not the domain layer that depends on the persistence layer but the other way around.
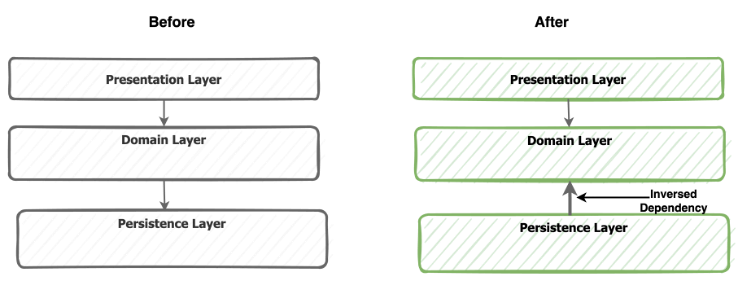
The consequence of using the DIP is that all dependencies point toward the domain layer, which doesn’t have any dependencies on the other layers, as illustrated in the diagram below.

The dependency is inversed between the Business layer and the persistence layer, as you can see in the following diagrams before and after applying the DIP.
Clean Architecture
This approach is known as Hexagonal Architecture, Onion Architecture, and Clean Architecture. It still uses a layered architecture, in addition to relying on DIP to inverse the dependencies between layers, particularly the domain layer, as we have seen earlier.
That means that the domain code must not have any outward-facing dependencies. Instead, with the help of the DIP, all dependencies point toward the domain code. In this architecture, the dependencies between the layers point “inward” toward the domain code, as illustrated in the diagram below.
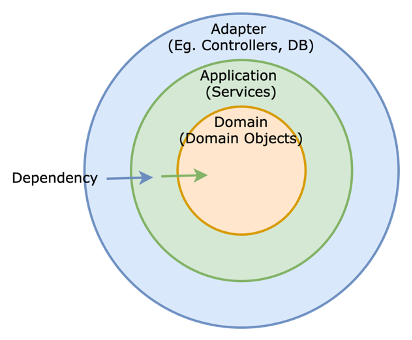
Layers
The clean architecture still uses a layered architecture but separates the layers differently:
Adapter Layer
This layer is responsible for interacting with the external “world”, such as the Web and the Databases. This layer doesn’t contain any business logic. The following are some examples of tasks that this layer can perform:
- Receives and maps the HTTP requests to Java (or another language) objects and returns HTTP responses
- Validates request inputs
- Check the authorizations
- Returning validation errors to calling clients
Application Layer
The primary role of this layer is to implement use cases and business processes. For example, submit your payment for books in your shopping cart. All the logic related to orchestrating the calls between the database and external interfaces (call to external payment interfaces) to accomplish the logic of use cases.
This layer depends only on the Domain layer and doesn’t depend on the Adapter layer.
Domain Layer
The domain objects used in this layer will contain business logic related to a specific domain object instance. Avoid t have anemic classes that have methods such as setter and prefer instead rich classes which include business logic, as illustrated in the code below.
public class Quote {
private final QuoteId id;
private QuoteStatus status;
private final LocalDate dateCreated;
public static Quote createNewQuote(Coverage coverage, Customer customer) {
}
public long calculatePremium(...) {
}
public void cancelQuote(...) {
}
public void addCoverage(Coverage coverage) {
}
}The code in this layer doesn’t have any dependency on other layers. Therefore, changes in other layers don’t affect them. For example, if we decide to use another framework than Spring Boot or another type of database (E.g., NoSQL) those changes will occur on the Adapter layer and will have no or limited impacts on the domain layer. In addition, the code becomes easily testable as it doesn’t depend on any other code or infrastructure.