

Matching a resume to a job description is harder than it looks. Deciding how well a candidate fits a role involves reading between the lines, weighing trade-offs, and making judgment calls that are difficult to standardize.
This is the problem Resume Fit Scorer was built to explore: how do you design an AI system that brings consistency and transparency to that evaluation, without pretending that a model can replace human judgment?
What is Resume Fit Scorer
Resume Fit Scorer is an AI-powered evaluation tool that compares a resume against a job description and returns a structured, explainable fit assessment.
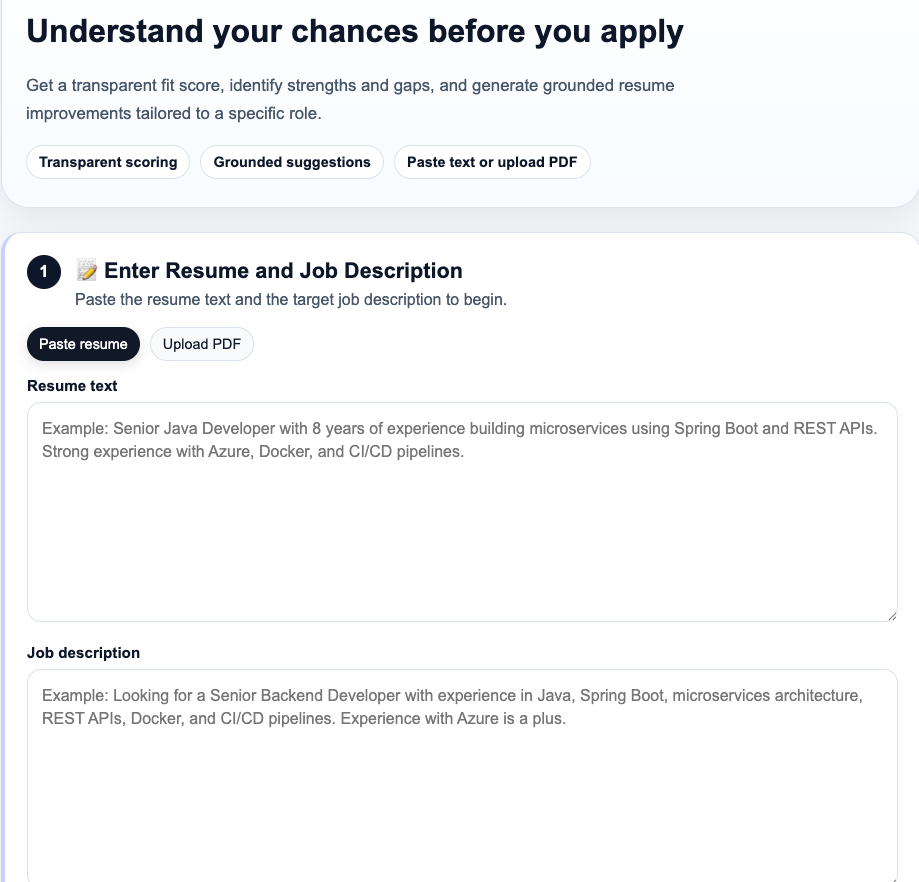
You provide a resume, either as pasted text or as a PDF, along with a job description. The tool processes both inputs, analyzes the match across multiple dimensions, and returns a result that includes a numerical fit score, a breakdown of how that score was computed, a list of strengths and gaps, and concrete suggestions for improving the resume.
Architecture Overview
The system follows a layered, responsibility-driven architecture with four clearly separated components.
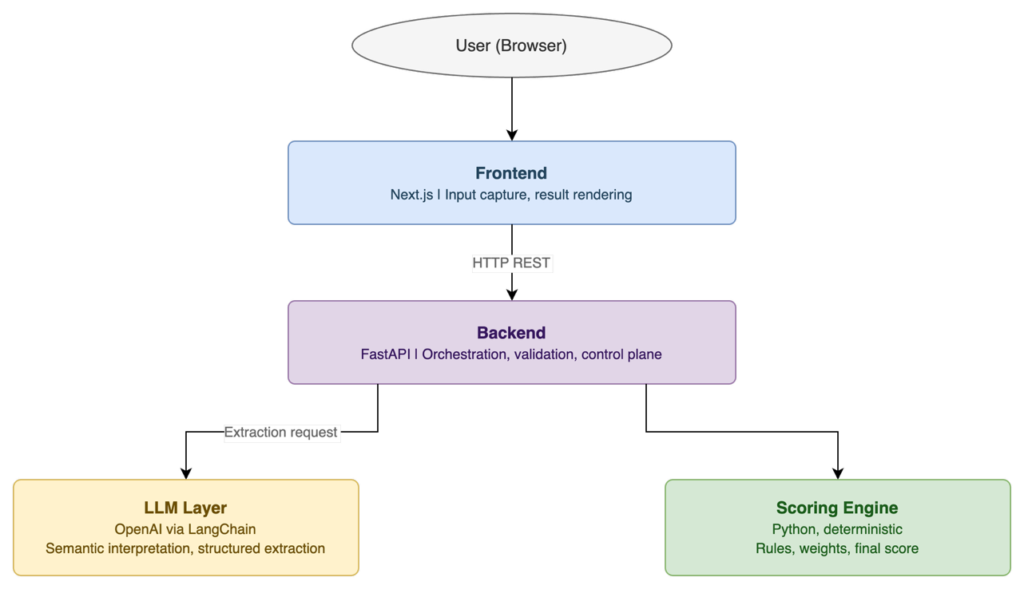
The frontend handles user interaction only. It captures input, manages file uploads, and renders results. It contains no business logic, no scoring rules, and no direct AI calls. This separation means the evaluation logic can evolve independently of the UI.
The backend is the system’s control plane. It receives requests, validates and normalizes inputs, orchestrates calls to the LLM, and then passes the structured output to the scoring engine. It enforces the boundary between what the LLM is allowed to decide and what the deterministic engine decides.
The LLM layer is responsible for semantic interpretation. It reads the resume and job description, extracts structured information, and maps indirect expressions to canonical skills and concepts. It does not produce scores. It produces evidence.
The scoring engine takes that evidence and applies predefined rules and weights to compute the final score. It is purely deterministic. Given the same structured input, it will always produce the same output. This is what makes the system explainable and auditable.
Key Design Decisions
1. Separating reasoning from scoring
Language models can produce plausible-sounding scores with justifications attached, which makes them feel reliable. But plausible is not the same as consistent. The same resume and job description, submitted twice with slightly different phrasing, can produce meaningfully different scores if the model is the sole decision-maker.
The solution is to restrict the LLM to a tightly scoped task: extract structured information and provide evidence-grounded assessments of specific attributes. The scoring logic (weights, thresholds, aggregation) lives entirely in the Python scoring engine. This means the score is always reproducible, auditable, and explainable without reference to model internals.
2. Making explainability a first-class requirement
Every skill assessment the LLM produces must include two things: a proficiency level and the textual evidence from the resume that supports it. If the model infers Docker experience from a phrase like “managed container-based deployment pipelines,” it must record both the inference and the source phrase. The scoring engine then works with explicit evidence rather than implicit model confidence.
For every point in the fit score, there is a traceable chain: score component, weight, LLM-extracted attribute, and evidence from the resume. That chain is what makes the output useful.
3. Handling input variability
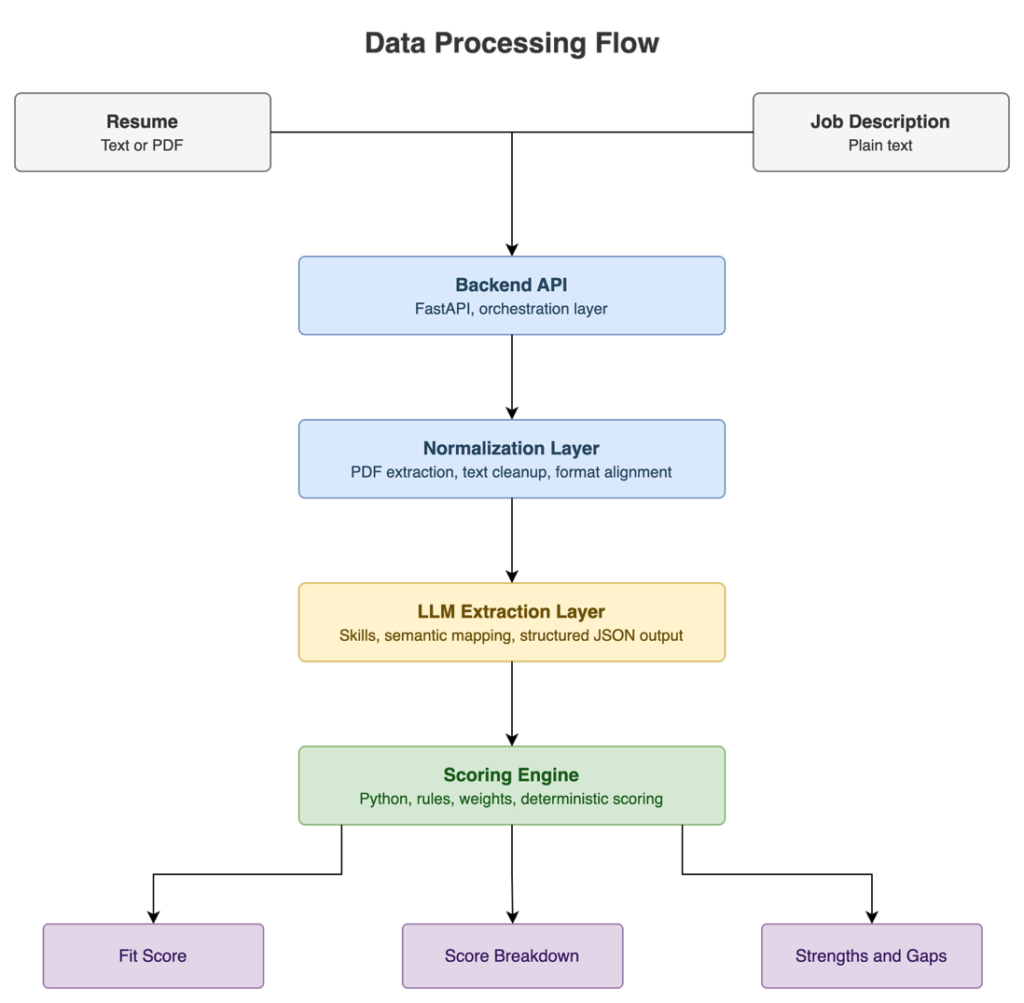
PDF extraction introduces variability in the input, including inconsistent line breaks, flattened structure, and loss of formatting. In contrast, pasted text may preserve a different structure depending on how it is copied. Treating these inputs as equivalent without preprocessing can lead to inconsistent interpretation by the LLM and ultimately impact scoring.
To address this, a normalization step was introduced between input parsing and LLM processing. Both PDF-extracted text and pasted input are passed through a lightweight normalization layer that standardizes whitespace and line structure. The goal is not to fully reconstruct the original document, but to reduce variability enough so that the same resume, regardless of input format, produces comparable analytical results.
4. Scoring dimensions
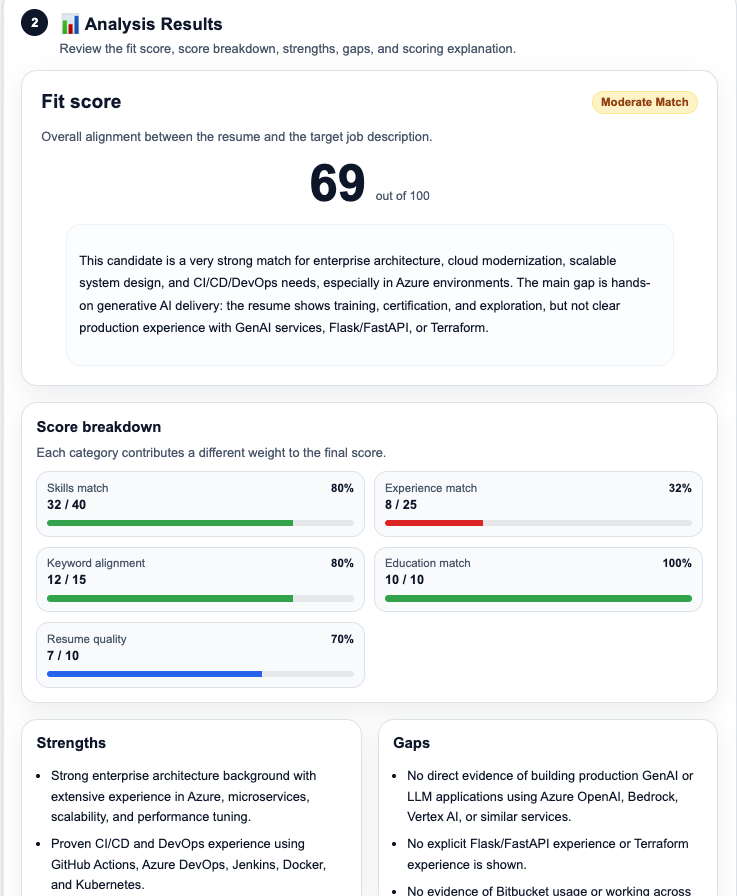
The scoring engine evaluates fit across five dimensions, each with its own weight:
- Skills match: alignment between candidate skills and required skills in the job description.
- Experience relevance: relevance of work history relative to role requirements.
- Keyword alignment: presence of role-specific terminology, accounting for synonyms and related terms.
- Education fit: degree level, field relevance, and any specific certifications required
- Resume quality: structural clarity, specificity of descriptions, and presence of quantified achievements.
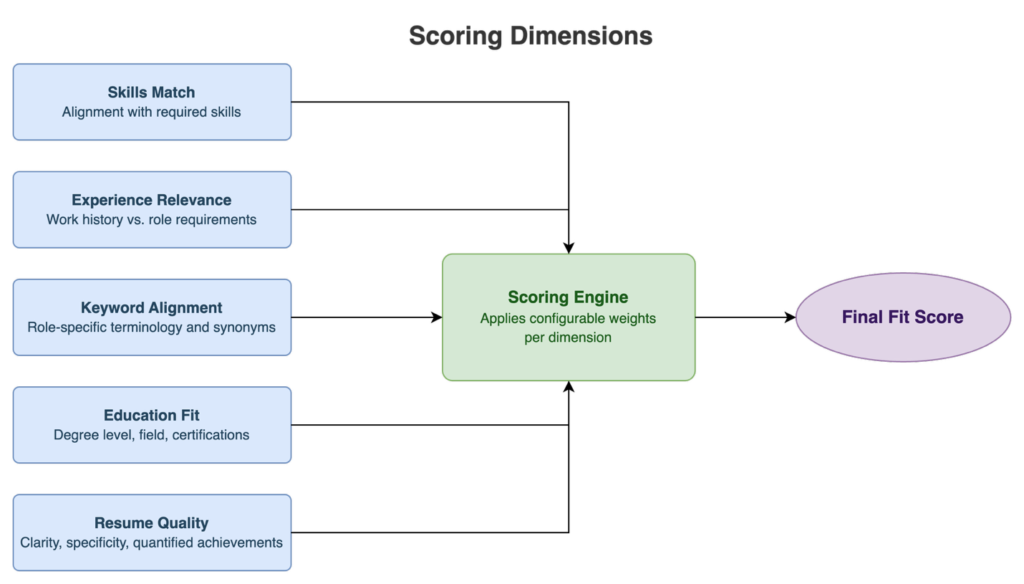
Although the weights are currently hard-coded, they could be made configurable to adapt the tool for various roles or industries without altering its architecture.
LLM Approach and Prompting Strategy
The LLM performs three core tasks: structured extraction of candidate profile data, semantic mapping of resume content to job requirements, and evidence-based gap analysis. It does not summarize, recommend, or score.
The prompts are designed with two priorities: structure and constraint. Every prompt specifies a precise JSON output schema. The model is not allowed to produce free-form text in response to these calls. This eliminates the parsing ambiguity that makes LLM integration in production systems fragile.
Each prompt follows a consistent structure: context framing, task definition, output schema specification, and constraint instructions. The constraint section is where hallucination risk is most actively managed. The model is explicitly instructed not to add skills absent from the resume, not to assess proficiency beyond what the text supports, and to clearly flag any inferences.
Despite these controls, LLM variability remains. Phrasing nuances in the input can still affect extraction quality, and the model’s understanding of domain-specific terminology varies by field. The architecture acknowledges this and compensates by keeping all final decision logic outside the model.
Why LangChain
A natural question when looking at this project is why LangChain was used at all, given that the OpenAI API can be called directly.
The answer is structure. Resume Fit Scorer does not need the LLM to generate text freely. It needs the LLM to behave like a structured data extractor, returning consistent, well-formed JSON that the scoring engine can process reliably. LangChain provides the prompt templating and output parsing abstractions that enforce that contract.
It also improves the separation of concerns. Prompt logic is isolated from the rest of the backend, allowing prompts to be updated and iterated on without affecting the scoring engine or the API layer.
Deployment
The application is deployed on Vercel as a monorepo with two independently deployable components:
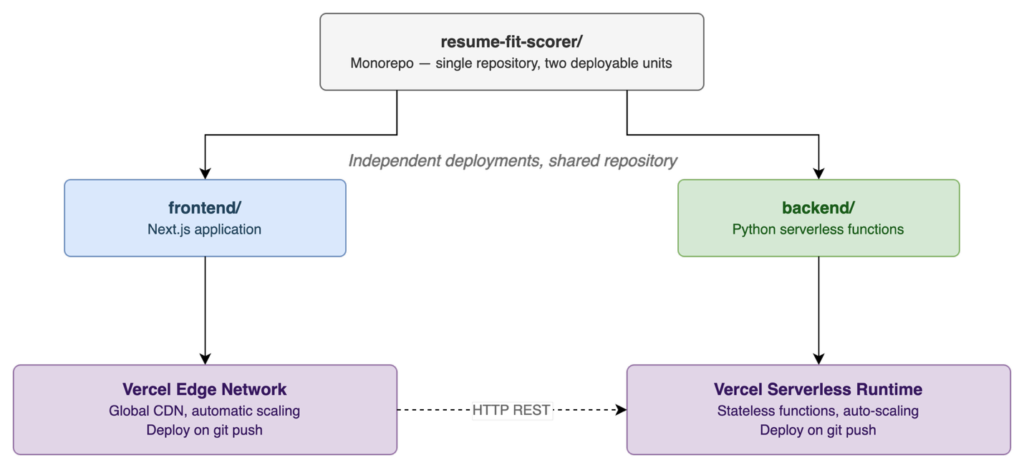
This structure allows the frontend and backend to evolve independently while sharing a single repository and version history.
The choice of Vercel was driven by a clear set of MVP priorities: minimize operational overhead, maximize deployment speed, and keep infrastructure simple enough that all focus can go into the product and architecture. Deployment is triggered by a git push. Scaling is automatic. For an MVP, that is exactly the right trade-off.
Use Cases
- For recruiters
A manual resume review is inherently subjective, and two reviewers looking at the same candidate against the same role will often reach different conclusions. Resume Fit Scorer applies a consistent evaluation model every time, surfacing the same dimensions in the same way, regardless of who is doing the screening.
The score breakdown also makes it faster to identify why a candidate does or does not fit, rather than requiring a full read-through. A recruiter can review the gap analysis in seconds and decide whether the shortfalls are deal-breakers or coachable. This tool fits most naturally as a first-pass filter. It does not replace human judgment in final decisions, but it reduces the volume of work that requires it.
- For job seekers
For candidates, the value is clarity. The tool identifies specific gaps between the resume and the job description and provides concrete suggestions for how to close them, not by fabricating experience, but by surfacing relevant experience that is already in the resume but not expressed in a way that aligns with the job description.
Limitations
PDF extraction quality varies significantly with document complexity. Heavily formatted resumes (multi-column layouts, embedded tables) produce noisier text than plain or lightly formatted documents. The normalization step mitigates this but does not fully solve it.
There is currently no persistence layer. Results are not stored, which means there is no ability to track a candidate’s progress over time, compare analyses across multiple job descriptions, or build a feedback loop from recruiter responses.
The scoring weights are also currently fixed. In a real deployment, different roles and industries have different weighting profiles. A senior engineering role weighs experience much more heavily than a graduate position, for example. Configurable profiles would make the system significantly more applicable across contexts.
Conclusion
In Resume Fit Scorer, every component has a clear responsibility. Every architectural choice was made with a specific trade-off in mind. The most important design principle is to use LLMs for semantic reasoning while keeping decision-making under deterministic control. That boundary, between what the model interprets and what the engine decides, is where the system’s reliability comes from.
From a personal standpoint, this project represents how I think about building AI systems: not as black boxes to be deployed and trusted, but as engineered systems with clear contracts between components, observable behavior, and honest acknowledgment of their own limitations.
Try It Yourself
If you want to see the concepts in this article in action, the tool is live and free to use. Paste your resume and a job description, and see your fit score in seconds: Try Resume Fit Scorer here
Questions, feedback, and technical discussion are welcome in the comments.