

If you’ve been following my series From Solution Architect to AI Architect, you know that my process is a mix of structure, curiosity, and improvisation. I built a learning plan with the help of an LLM, but I also promised myself that I’d stay flexible and adjust as I go. And that’s exactly what happened.
Even though RAG (Retrieval-Augmented Generation) wasn’t supposed to be my next milestone, I reached a point where I wanted to build something real. Something concrete. Something I could deploy, test, and maybe even turn into a small product.
RAG felt like the perfect next step, both theoretical enough to deepen my understanding of AI systems and practical enough to produce something tangible.
This blog documents my journey learning RAG: the concepts, the architecture, the steps I took, and the back-and-forth between theory and practice. If you’re an architect or developer on a similar learning path, I hope this helps you shape your own progression.
Introduction to RAG
Large Language Models (LLMs) are transforming the way we work. They can answer questions, summarize long documents, write code, and perform tasks that were once considered impossible. Yet, LLMs have an important limitation: they only know what they learned during training.
If someone asks you, “Why are hotels expensive on weekends?” you can easily answer using general knowledge. But if they ask, “What did we decide about the Q4 budget in last Tuesday’s meeting?” You need to consult your meeting notes. That information is nowhere to be found on the public internet.
LLMs face the same challenge. They have broad general knowledge from reading huge parts of the internet, but they can’t access your private documents and sometimes specialized knowledge in domains like healthcare or law.
When an LLM doesn’t have the information it needs, it may respond with generic answers or worse, hallucinate.
Retrieval-Augmented Generation (RAG) solves this problem by adding a retrieval step before the LLM generates its response. RAG operates in two main phases:
- Retrieval Phase: Find the most relevant information from a knowledge base.
- Generation Phase: Use that retrieved information to produce a grounded, accurate response.
This simple architecture dramatically improves the accuracy and relevance of LLM outputs, especially for enterprise use cases, private datasets, and specialized knowledge domains.
Real-World Examples of RAG Applications
Customer Service Chatbots
Most companies want chatbots that actually understand their products, policies, and communication style. A chatbot trained only on general internet data won’t know your refund rules or internal procedures. That’s where RAG becomes useful. Imagine a customer asks: “What’s your return policy for electronics purchased during a sale?”
Here’s what happens in a RAG-powered system:
- The retriever searches the knowledge base for anything related to return policies, promotions, and electronics.
- It extracts the most relevant passages.
- The system builds an augmented prompt that combines the customer’s question and the retrieved policy text, then sends it to the LLM.
- The LLM generates an answer that is aligned with company rules.
Without RAG, the model might give a generic answer that violates company policy. With RAG, the chatbot becomes a real support tool.
Healthcare Systems
Some fields demand precision. Healthcare is one of them. Doctors rely on specialized, up-to-date information and cannot tolerate hallucinations. A RAG system can:
- retrieve the latest medical research
- analyse relevant clinical guidelines
- check drug interactions
- assist with rare case reviews
- support decisions using validated sources
Of course, privacy and security remain essential, but RAG allows the retrieval of information from private databases.
RAG Architecture at a High Level
At first glance, using a RAG system feels just like using an LLM. You ask a question, and you receive an answer. But inside the system, a few crucial steps happen before generation.
A RAG system has three core components:
- LLM (Large Language Model): Generates the final response.
- Knowledge Base: A collection of documents—PDFs, policies, wiki pages, emails, code, logs, etc.
- Retriever: Searches the knowledge base to identify the most relevant documents.
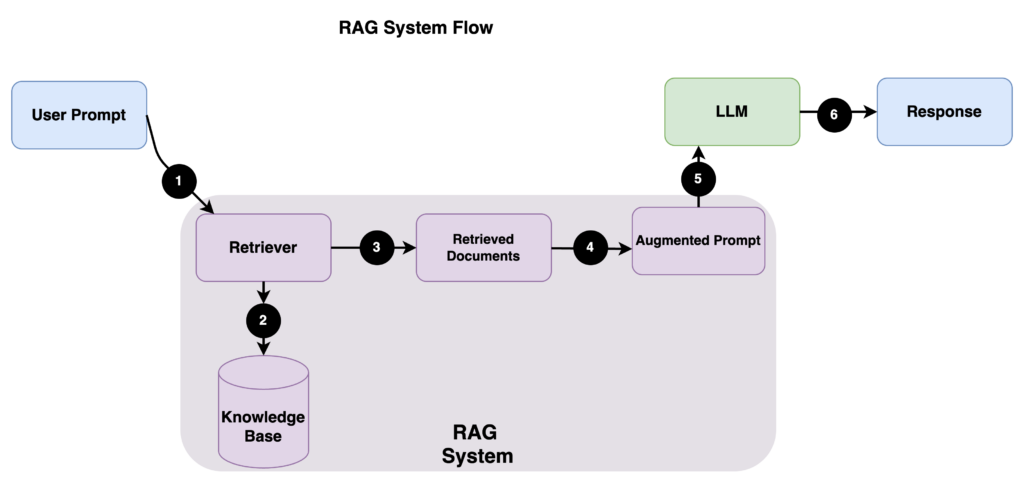
The workflow looks like this:
Step 1: User submits a prompt
Step 2: The retriever searches for the most relevant documents stored in the Knowledge Database.
Step 3: Retrieved documents are returned. Only a few high-quality, relevant documents are selected.
Step 4: The system adds the retrieved text to your original question, creates the augmented prompt, and then submits it to the LLM.
Step 5: The LLM generates the response using both its training knowledge and the retrieved context (augmented prompt).
Step 6: You receive a response.
My Learning Journey – Step by Step
My progression wasn’t linear. I moved between theory, practice, deployment, and curiosity. But looking back, I can clearly identify the steps that shaped my understanding.
Step 1: Building Core Understanding
I started with foundational concepts. I needed to understand what RAG is, how retrieval works, why hallucinations occur, and why retrieval is essential.
My primary resource is Deeplearning RAG course. I watched almost all the videos in Module 1 (RAG Overview) and Module 2 (Information Retrieval and Search Foundations). Both modules come up with ungraded samples that you can execute in their Jupiter Notebooks. The hands-on exercises helped me confirm that I was understanding the basics. I didn’t do the graded labs because I’m on the free plan.
This step gave me the vocabulary and intuition I needed before building anything serious.
Step 2: Deploying My First RAG System
Once I understood the fundamentals, I felt a strong desire to deploy something. Seeing a RAG application running in the cloud would motivate me.
I experimented by following a complete RAG project example and deploying it to an Azure cloud account. I learned:
- How a retriever integrates with an LLM
- How documents are indexed
- How the augmented prompt gets constructed
- How the app runs in a real environment
Deploying something live is a different feeling. It gives you confidence!
The only reason I chose Azure is my familiarity with the platform. Pick what you even know the most.
My costs exceeded $30 CAD over a couple of hours, primarily due to extensive experimentation with large PDF ingestion and retrieval. So, here’s my advice: track your expenses if you deploy in the cloud and delete resources as soon as you’re done.
Step 3: Deepening My Understanding of Retrieval
After my first deployment, I realized I needed to understand vector databases, embeddings, indexing, and retrieval strategies in more detail.
This step was harder than the previous ones. Some concepts were dense. I paused videos, replayed segments, and tried to accept that I didn’t have to master everything on the first pass. My goal wasn’t to become a data scientist; it was to understand enough to build RAG systems confidently. My main resource was again the Deeplearning RAG course, but this time I focused on Modules 3 to 5.
Step 4: Understanding LLM Internals
After retrieval came curiosity: How do LLMs actually generate tokens? How do transformers work?
Understanding this wasn’t strictly necessary for building a RAG project, but it helped me reason better about quality, latency, and limitations. It also improved my intuition when selecting model sizes or tuning parameters.
This was also the moment when I realized that building AI systems requires both engineering skills and a conceptual understanding of how models reason. My main courses for this step are: Module 4 in the Deeplearning RAG course and the short course How Transformer LLMs Work.
Step 5: Preparing to Build My Own Product (Next Blog)
At this point, I now feel ready to take everything I learned and build something real:
- a small product
- powered by RAG
- deployed in the cloud
- accessible through a UI
- and eventually shareable with the world
This will be the focus of my next blog. I want to take an idea, transform it into a prototype, deploy it, iterate, and show the whole process from architecture to implementation to lessons learned.
Final Thoughts
My journey learning RAG was not linear, clean, or perfectly organized, and I think that’s exactly how real learning works. We move forward when we’re motivated. We revisit theory when we hit limits. We deploy too early. We take notes too late. And somehow, step by step, it all comes together.
If you’re a developer or architect trying to navigate the world of AI, my advice is simple:
- Stay curious.
- Mix theory with practice.
- Build something even if it’s small.
- Don’t fear jumping ahead.
- And be careful about the cost if you deploy in the cloud.
In the next part of my series, I’ll take the next big leap: building and deploying my own RAG application.
Stay tuned; this is where the journey gets even more exciting.